I'd be interested in an analysis of the compiled assembly for those 5 versions in 2b. A quick test on my end shows them all to be extremely similar.
I know little assembly, and am not going to attempt to pick it apart, so I can't attest to any speed difference. But as an example the first and the last compile to the same, though the last has 2 fewer instructions and some -16s changed to -24s. The first is identical to the second. The third has a bit of shuffling, but also appears identical to the first. And the last two are identical to each other (well, obviously).
How much optimization are you looking for in your C-code vs your coder's productivity? If they can get the last ones in one shot, all well and good, but if not is refactoring worth anything in this case?
edit: with -O3 optimizations on gcc, they all appear to be literally identical, the only differences I can see being variable names and the order of functions (in code, not in call order) between the first three and the last two.
Indeed - these are issues that I will be discussing, and would discuss with a candidate once I had their code in hand. I say in 2b:
Each of these changes is unnecessary and in some cases
damage readability. Further, a good compiler will get
most, if not all, of the efficiency for you without
making these changes.
If changes damage readability and don't change the compiled code, don't make them!
Readability has to be balanced against efficiency, but too often people think something is more efficient when it isn't. As always, profile before "improving."
As I say, these are issues for discussion. Let me add at this point that some of the submitted versions, and some of my reference versions, are significantly different in both style and efficiency.
I'll definitely follow along, it's been interesting. And I'd probably come up with something like the last one after a little thought, because it's pretty idiomatic of string copying.
I just tend to seriously dislike code refactoring instead of algorithm refactoring, and anything that advocates it. Typically, the compiler is far better than the coder, especially when you turn on optimizations, but the compiler (nearly) can't swap out your code for a better algorithmic approach. Thus, you'd be much better off with expansive, seemingly inefficient code from a smart programmer who knows the be(st|tter) algorithm(s).
It wasn't intended for that purpose, but stand by ...
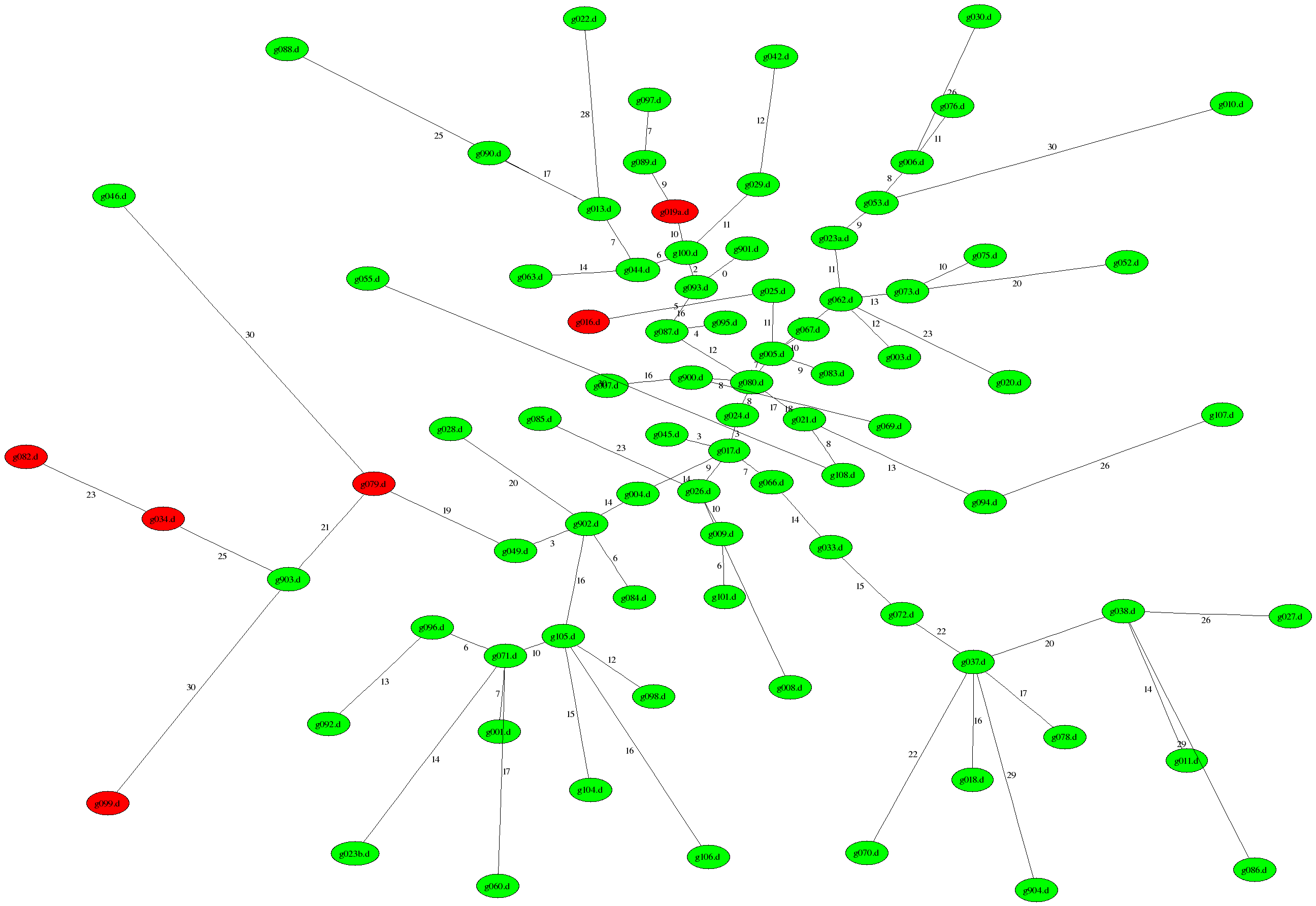
EDIT: OK, I've uploaded a larger version where the labels are readable, but I've had to change the layout so the nodes don't overlap. The lengths of the edges are now not always realted to the distance, although it's approximate.
Note: Yours might still not be on it, as yours might be one of the outliers. You can email me your ID and I'll try to find time to send you some data. Or you can wait.
Thanks - that's a bit better of a teaser. I'm happy to see mine isn't red, but it's pretty tightly clumped in the main group of solutions. That's not really surprising as it's not that far off from your reference solution, which seems to be the most straightforward way to go about it.
Yeowch! Mine (g034.d) shows up as the second red dot from the left. I submitted a quick pseudocode answer without any research in an effort to mimic interview whiteboarding conditions.
I had no idea my solution would be automatically validated - I was happy enough to get an in-place O(n) solution. The complete lack of pointers on my part must be what separated me from the cluster of correct solutions at the center.
The 900's are my reference solutions. I'm intending to create solutions with the various feature sets to try to create clumps around them. If there are suitable submissions, I'll just identify and use them instead. For example, g080.d is pretty central.
I'm replacing recognised keywords with their initial letter, other symbols with "x", removing all spacing, retaining all punctuation, and then using a Levenshtein distance.
I'm debating inserting braces around every block to assist with the similarity concept, but that's hard to do automatically without fully parsing the routine. The above "fingerprint" would then become this:
Did you consider tokenizing the inputs and comparing those? Based on Levenshtein distance alone you're basically saying that "++" and "!=" are twice as important as "=" or "*", which doesn't seem right to me.
Next question: How are you picking (x,y) coordinates for the graph? You've explained how you determine the connectivity, but the positioning is a bit unclear -- edges with the same score often have quite different lengths.
I did consider tokenising the inputs, and probably will. The only reason not to have done so yet was that this was a no-brainer in terms of getting something working just to see if produced something useful.
I'm using neato for the layout. Graph layout is hard, and in some cases unsolved. I'm using this for rough visualisation, then I'll write code to find true clusters.
Put every node in its own component. Find the shortest edge that joins two components, emit that edge, merge the components. Lather, Rinse, Repeat.
Also, braces penalise you twice. Code that is identical except that one includes, the other excludes, a pair of braces are distance 2 apart. There is some reason to say they should have distance 0. Fully parenthesised code, and then ignore the close (or open) brace would fix that.
This one is awesomely embarassing. I submitted a quick response, but it turned out to (probably) be quite pessimal. Heh.
The challenge was of the category that triggers my "oh, that's easy!" knee-jerk response, and I still think it's easy. It's just that my knee didn't jerk towards the solution shown by RiderOfGiraffes, which really feels like the best one. :)
I think I'll blame job stress for my performance when it comes to this one.
whew! I'm glad I passed, though it should be obvious from my submission that my C is far from fluent! I am looking forward to the analysis - thank you for doing this RoG!
{kind=link}
I know little assembly, and am not going to attempt to pick it apart, so I can't attest to any speed difference. But as an example the first and the last compile to the same, though the last has 2 fewer instructions and some -16s changed to -24s. The first is identical to the second. The third has a bit of shuffling, but also appears identical to the first. And the last two are identical to each other (well, obviously).
How much optimization are you looking for in your C-code vs your coder's productivity? If they can get the last ones in one shot, all well and good, but if not is refactoring worth anything in this case?
edit: with -O3 optimizations on gcc, they all appear to be literally identical, the only differences I can see being variable names and the order of functions (in code, not in call order) between the first three and the last two.